Why this matters: RAG is the enterprise standard for AI. If you want a model to know your private data, you need RAG.
Attention Activity: The Hallucination Engine
Before understanding RAG, we must understand the problem it solves. Watch what happens when a standalone LLM lacks factual, up-to-date information.

Try asking the mock standalone AI below about a highly specific or recent piece of proprietary data.
Knowledge Check 1
Why do standalone LLMs "hallucinate" answers when asked about specific company internals?
Core Idea of Retrieval-Augmented Generation
RAG works by combining a search engine (Retrieval) with a language model (Generation). Instead of relying on what the model memorized during training, RAG looks up facts on the fly.
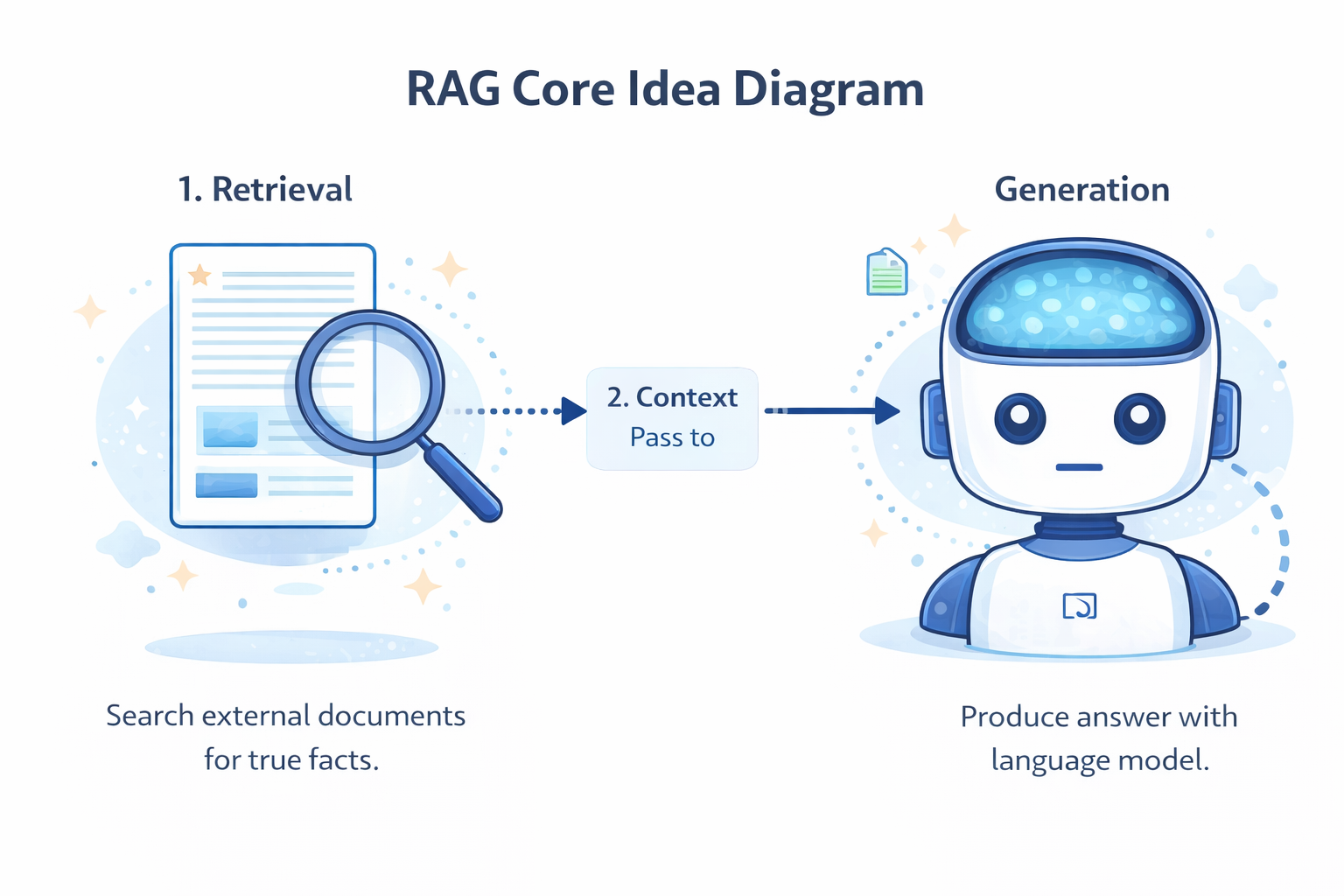
1. Retrieval
Search external documents for true facts.
2. Context
Pass the facts to the LLM.
3. Generation
LLM drafts a grounded, factual answer.
By splitting the job into "finding information" and "formatting information," RAG guarantees the model only uses the exact facts you provide, dramatically reducing hallucinations.
Knowledge Check 2
Which step of the RAG pipeline involves converting the user's prompt into a search query to find relevant facts?
High-Level RAG Pipeline
Here is the standard flow that happens behind the scenes every time a user submits a prompt to a production RAG system:
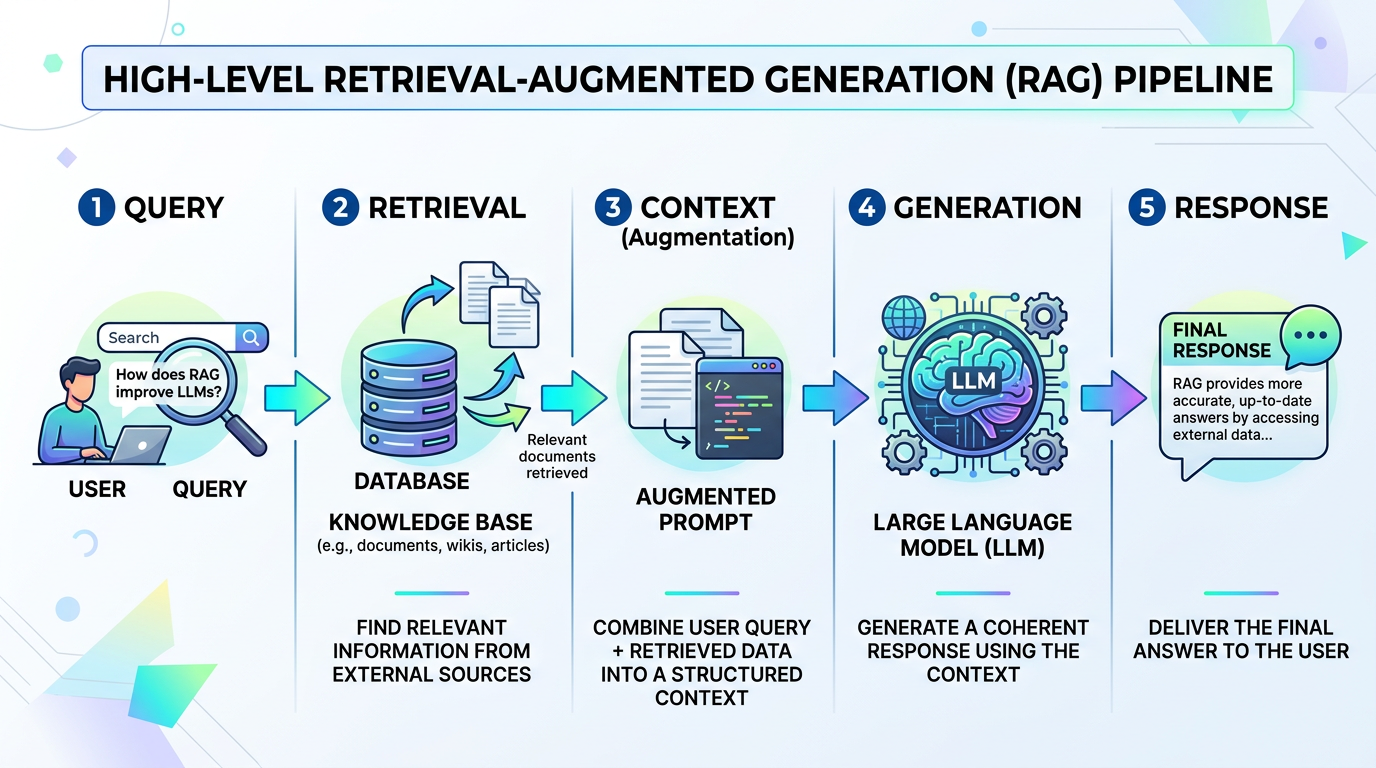
- Query: The user asks a question via the chat interface.
- Retrieval: The system converts the query into a search, finds relevant chunks from a database, and scores them.
- Context: The top-scoring chunks are silently appended to the user's prompt as "context."
- Generation: The LLM reads the context and generates the final output using only the provided facts.
- Response: The accurate answer is sent back to the user.
Role of External Knowledge Sources
RAG is only as good as the data you connect it to. You can infinitely extend an LLM's capability by hooking it up to various external sources.

Embeddings and Vector Databases
How does the RAG system actually find the right documents? It relies on Vector Embeddings.
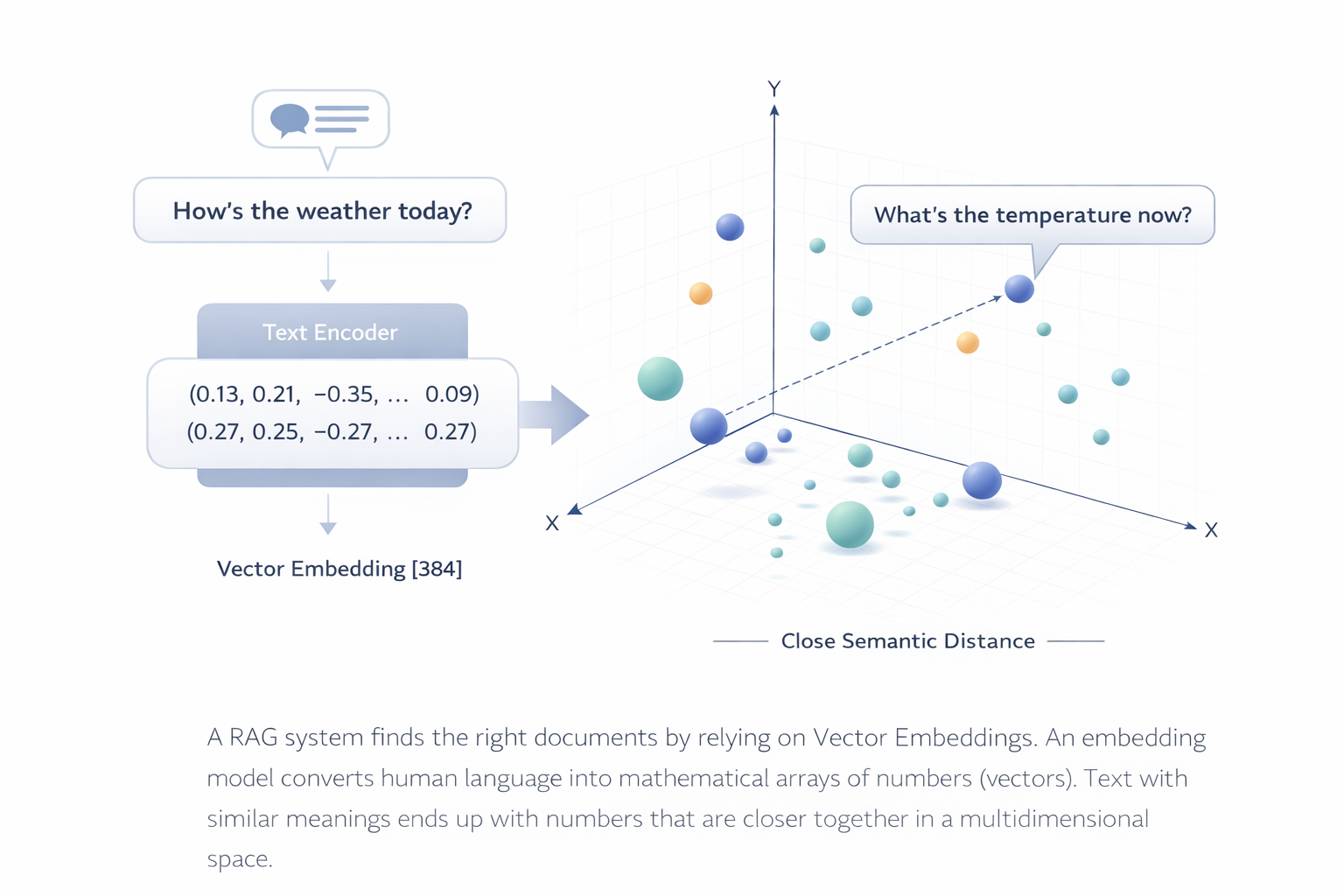
An embedding model converts human language into mathematical arrays of numbers (vectors). Text with similar meanings ends up with numbers that are closer together in a multidimensional vector space.
Knowledge Check 3
What is the primary function of an embedding model in the retrieval process?
RAG vs Fine-Tuning
A common misconception is that you must "fine-tune" a model to teach it new facts. In reality, RAG is vastly superior for injecting new knowledge dynamically.
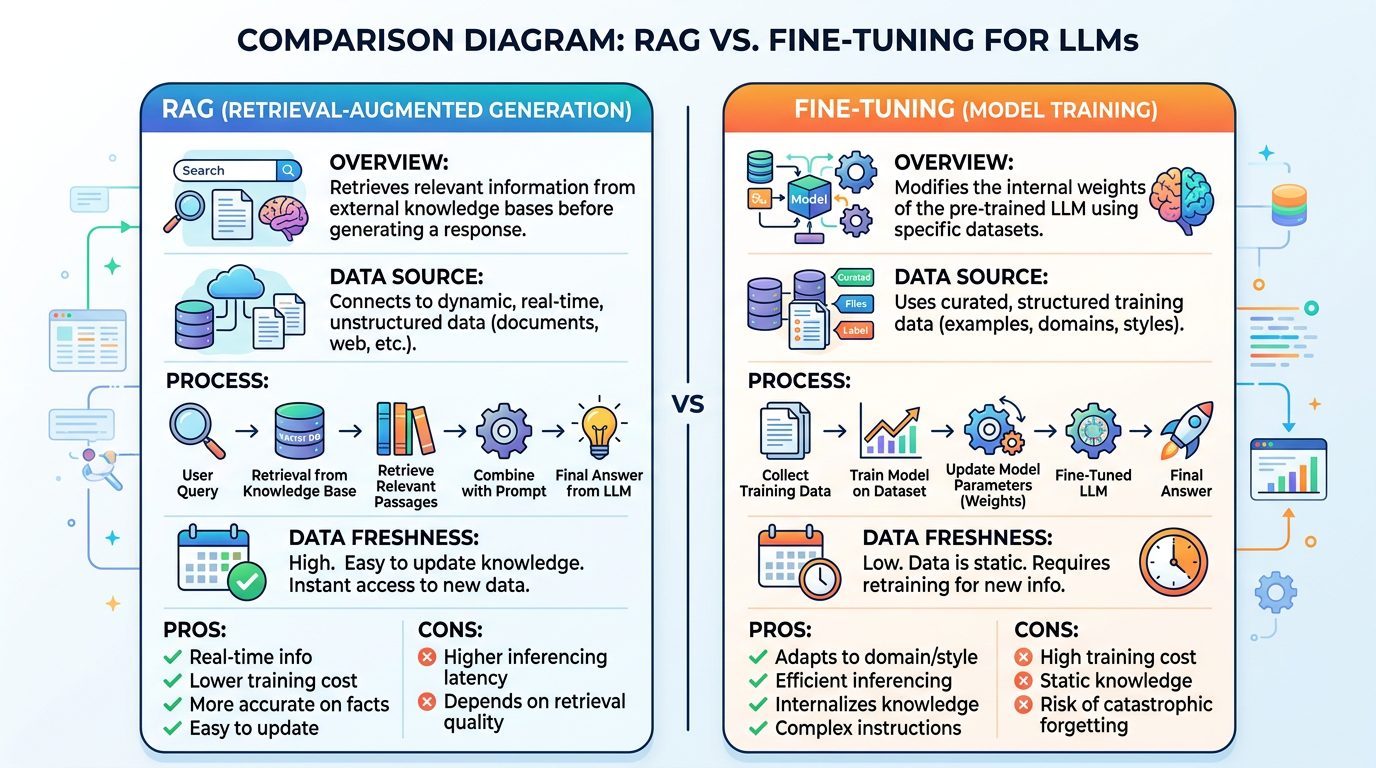
| Feature | RAG | Fine-Tuning |
|---|---|---|
| Best for... | Adding new, dynamic facts and private data | Teaching style, tone, or response format |
| Knowledge Updates | Instant (Update the DB) | Slow (Retraining needed) |
| Cost & Effort | Low to Medium | High (Needs curated datasets) |
Knowledge Check 4
When should you prefer Fine-Tuning over RAG?
Vector Databases in Action
A vector database is optimized for storing and querying numerical embeddings. It ensures lighting-fast retrieval even with millions of documents.

When a query is received, the vector DB performs a K-Nearest Neighbors (KNN) search or approximate similarity search to find the closest vectors. It can also filter by metadata (e.g., date, author) to refine results before sending them to the LLM.
Advanced RAG: Document Chunking
You can't pass an entire 500-page manual to an LLM at once. You must break documents into smaller "chunks" before embedding them.

Proper chunking is an art. Too small, and the context is lost. Too large, and the model gets overwhelmed or the retrieval precision drops. Most pipelines also include a "re-ranking" step to ensure the very best chunks are fed to the model first.
Summary & Key Takeaways
- Standalone LLMs Hallucinate: Without external context, models invent facts when asked about proprietary or recent data.
- RAG (Retrieval-Augmented Generation): Combines search with text generation to ground answers in truth.
- The Pipeline: Query → Retrieval (Vector Search) → Context → Generation → Response.
- Embeddings: Text is converted into numerical vectors to find semantically similar information quickly.
- RAG vs Fine-Tuning: Use RAG for teaching facts; use fine-tuning for teaching tone and style.
- Chunking: Large documents must be systematically broken down for accurate embedding and retrieval.
Final Assessment
You have reached the end of the lesson content. Now, test your knowledge with a short 5-question assessment. You must score 80% or higher to earn your certificate.
Ready to begin?
Assessment Q1
What is the primary purpose of Retrieval-Augmented Generation (RAG)?
Assessment Q2
In the context of the RAG pipeline, what happens during the "Context" phase?
Assessment Q3
When should you prefer RAG over Fine-Tuning?
Assessment Q4
What is the role of an Embedding Model in RAG?
Assessment Q5
Why must large documents be "chunked" before being used in a vector database?